Lab 02 — ALB + Auto Scaling Group: Alta Disponibilidad Real¶
Lo que construimos: Encima de la VPC del Lab 01, agregamos un Application Load Balancer que distribuye tráfico entre múltiples EC2s, y un Auto Scaling Group que lanza y destruye instancias automáticamente según la carga — lo que AWS llama "elasticidad".
Servicios: Application Load Balancer, Target Group, Launch Template, Auto Scaling Group, CloudWatch, EC2
Duración: ~2.5 horas
Costo: ~USD $0.02/hora mientras el ALB está activo (el ALB no es Free Tier). Las EC2 t2.micro sí son Free Tier.
Arquitectura final del lab¶
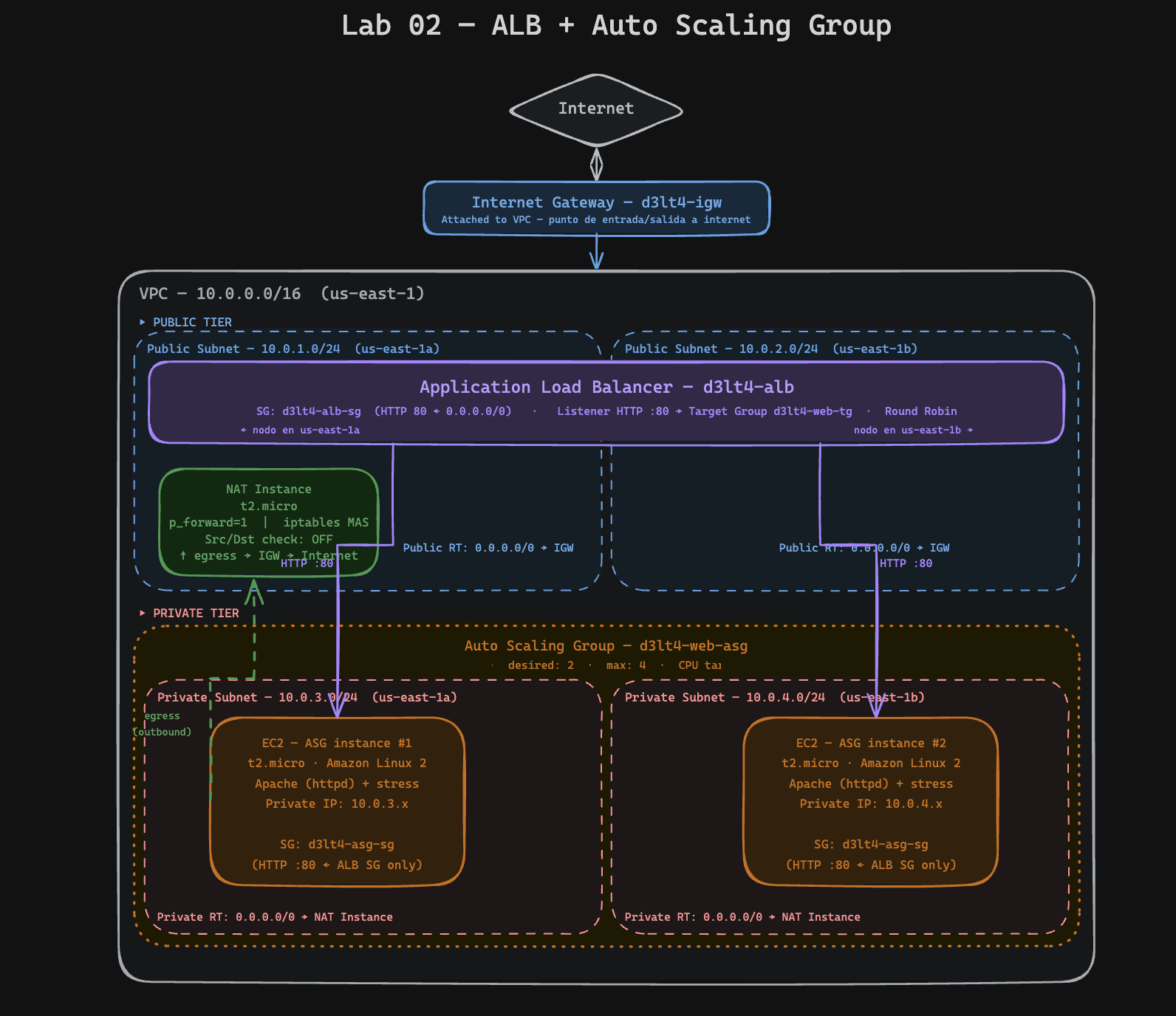
El problema que resolvemos¶
El web server del Lab 01 funciona, pero tiene un problema serio: es un SPOF (Single Point of Failure). Si esa EC2 se cae — por un bug, una actualización que rompe algo, o un problema de hardware en el datacenter de AWS — el sitio se cae. No hay plan B.
En producción esto no es aceptable. La solución son dos conceptos que van juntos:
- Alta disponibilidad (HA): El sistema sigue funcionando aunque algún componente falle. Se logra teniendo múltiples instancias en múltiples AZs — si
us-east-1atiene un problema, las instancias enus-east-1bsiguen respondiendo. - Elasticidad: El sistema adapta su capacidad a la demanda. Si de repente tenés 10x el tráfico, AWS lanza más instancias automáticamente. Cuando el tráfico baja, las destruye para no pagar de más.
Un Application Load Balancer resuelve la distribución del tráfico. Un Auto Scaling Group resuelve la elasticidad. Juntos, son la base de cualquier arquitectura resiliente en AWS.
Parte 1 — Launch Template + Security Groups¶
Qué es un Launch Template¶
Un Launch Template es un "blueprint" para lanzar instancias EC2. Define todo lo necesario: la AMI, el tipo de instancia, la Key Pair, los Security Groups, el User Data. Cuando el Auto Scaling Group necesita lanzar una nueva instancia, usa este template — así todas las instancias son idénticas sin que tengas que configurarlas a mano.
Es la evolución de los "Launch Configurations" (deprecados por AWS). La diferencia clave: los Launch Templates son versionables. Podés tener v1 con t2.micro y v2 con t3.micro, y hacer rollback si algo sale mal.
Por qué cambiamos la arquitectura de seguridad¶
En el Lab 01, el web server (d3lt4-web-sg) aceptaba HTTP desde 0.0.0.0/0 (cualquier IP). Con ALB, podemos mejorar esto:
ANTES (Lab 01): Internet → EC2 (HTTP directo)
DESPUÉS (Lab 02): Internet → ALB → EC2 (solo acepta tráfico del ALB)
Las instancias del ASG no necesitan ser accesibles desde internet directamente — solo el ALB lo necesita. Configuramos los Security Groups para que las instancias solo acepten HTTP desde el SG del ALB. Si alguien intenta conectarse directo a la IP privada de una instancia, el SG lo bloquea.
Esto reduce la superficie de ataque: el único punto de entrada HTTP es el ALB, que podemos proteger con WAF, rate limiting, etc.
1.1 Security Group para el ALB¶
- Ir a EC2 → Security Groups → Create security group
- Name:
d3lt4-alb-sg - Description:
ALB - HTTP publico - VPC:
d3lt4-vpc -
Inbound rules → Add rule:
Type Port Source Descripción HTTP 80 0.0.0.0/0(Anywhere IPv4)HTTP público al ALB -
Create security group
- Anotá el SG ID — lo necesitás para el siguiente paso
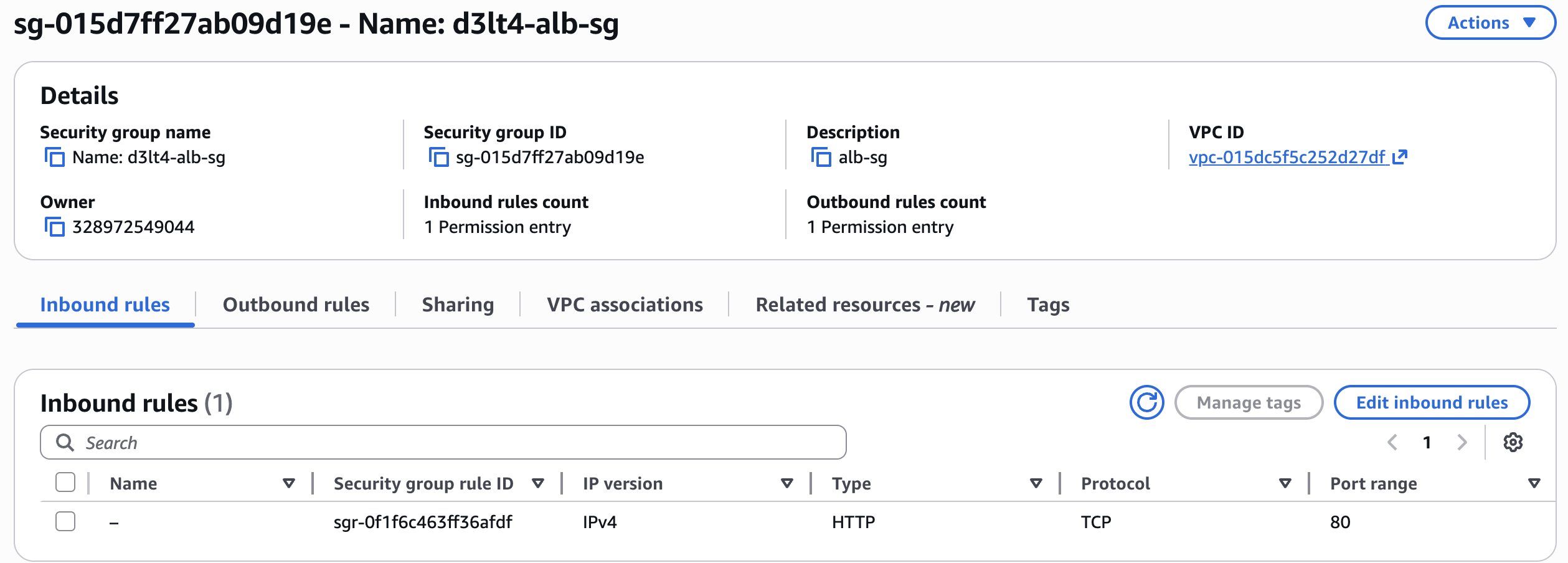
d3lt4-alb-sg— inbound HTTP 80 desde el SG del ALB.
1.2 Security Group para las instancias del ASG¶
Este SG lo van a tener las EC2s que lance el Auto Scaling Group. Solo aceptan HTTP desde el ALB (no desde internet) y SSH desde las subnets públicas (para poder entrar desde la NAT como bastion si necesitás debuggear).
- EC2 → Security Groups → Create security group
- Name:
d3lt4-asg-sg - Description:
ASG instances - HTTP solo desde ALB - VPC:
d3lt4-vpc -
Inbound rules → Add rule:
Type Port Source Descripción HTTP 80 SG: d3lt4-alb-sgHTTP solo desde el ALB SSH 22 10.0.1.0/24SSH desde subnet pública (NAT/bastion) SSH 22 10.0.2.0/24SSH desde subnet pública
Source = Security Group
En vez de poner un CIDR de IP, podés referenciar otro Security Group como fuente. Si el ALB escala o cambia de IPs internas, la regla sigue funcionando porque apunta al SG, no a IPs fijas.
- Create security group
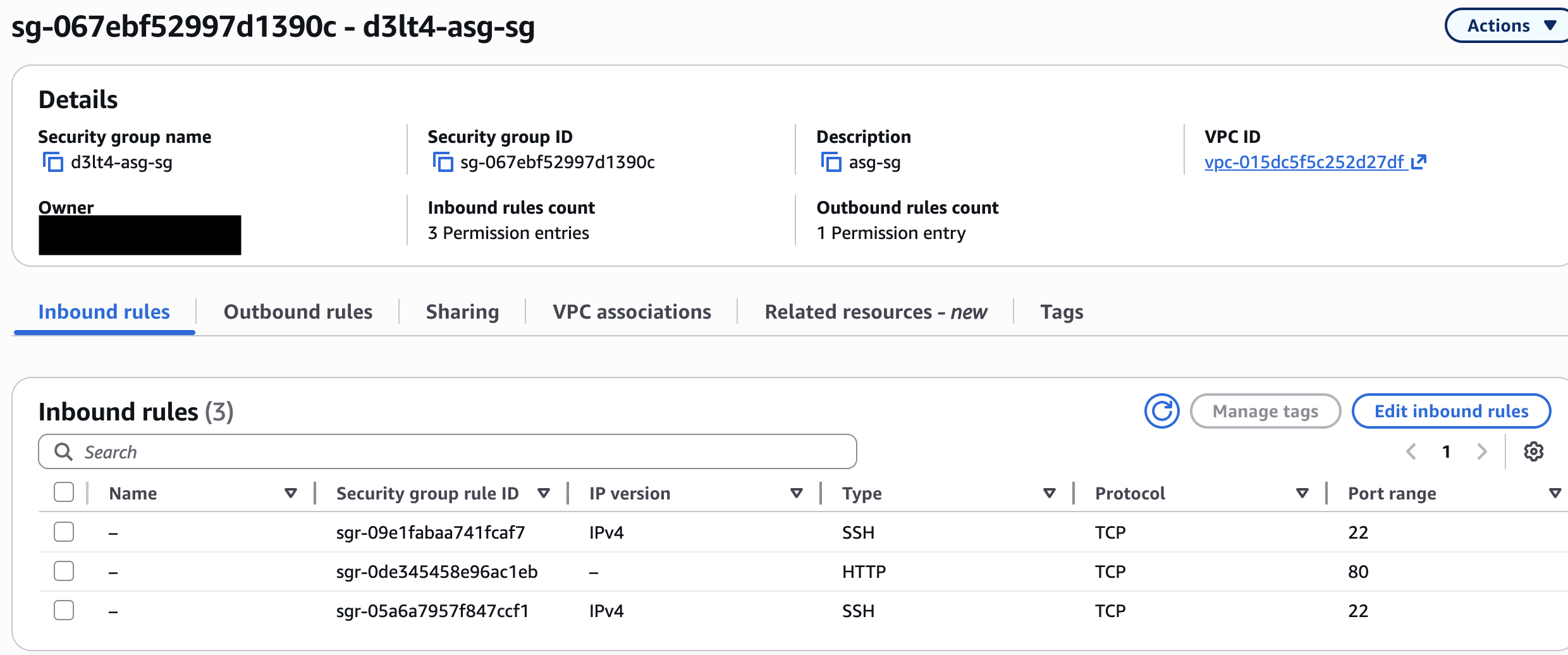
d3lt4-asg-sg— 3 reglas inbound: HTTP desde ALB SG, SSH desde ambas subnets públicas.
aws ec2 create-security-group \
--group-name d3lt4-asg-sg \
--description "ASG instances - HTTP solo desde ALB" \
--vpc-id $VPC_ID
export ASG_SG="sg-XXXXXXXXX"
# HTTP solo desde el ALB (source = SG del ALB)
aws ec2 authorize-security-group-ingress \
--group-id $ASG_SG \
--protocol tcp --port 80 \
--source-group $ALB_SG
# SSH desde subnets públicas
aws ec2 authorize-security-group-ingress \
--group-id $ASG_SG --protocol tcp --port 22 --cidr 10.0.1.0/24
aws ec2 authorize-security-group-ingress \
--group-id $ASG_SG --protocol tcp --port 22 --cidr 10.0.2.0/24
1.3 Crear el Launch Template¶
El Launch Template incluye el User Data que configura el web server. La página muestra el Instance ID y la AZ de cada instancia — así cuando el ALB distribuya tráfico podés ver en el browser cuál instancia está respondiendo.
- Ir a EC2 → Launch Templates → Create launch template
- Launch template name:
d3lt4-web-template - Template version description:
v1 - Lab 02 ALB + ASG - AMI: Amazon Linux 2 (Free tier eligible)
- Instance type:
t2.micro - Key pair:
d3lt4-key - Network settings:
- No especificar subnet (el ASG define en qué subnet lanzar)
- Security groups:
d3lt4-asg-sg
- Advanced details → scroll hasta User data, pegar este script:
#!/bin/bash
yum update -y
yum install -y httpd stress
systemctl start httpd
systemctl enable httpd
TOKEN=$(curl -s -X PUT "http://169.254.169.254/latest/api/token" \
-H "X-aws-ec2-metadata-token-ttl-seconds: 21600")
INSTANCE_ID=$(curl -s -H "X-aws-ec2-metadata-token: $TOKEN" \
http://169.254.169.254/latest/meta-data/instance-id)
AZ=$(curl -s -H "X-aws-ec2-metadata-token: $TOKEN" \
http://169.254.169.254/latest/meta-data/placement/availability-zone)
LOCAL_IP=$(curl -s -H "X-aws-ec2-metadata-token: $TOKEN" \
http://169.254.169.254/latest/meta-data/local-ipv4)
# Color distinto por AZ para identificar visualmente qué instancia responde
if echo "$AZ" | grep -q "1a"; then
AZ_COLOR="#1f6feb"
else
AZ_COLOR="#388bfd"
fi
cat << HTML > /var/www/html/index.html
<!DOCTYPE html>
<html>
<head><title>D3LT4 Protocol — Lab 02</title>
<style>
body { background:#0d1117; color:#c9d1d9; font-family:monospace; padding:40px; }
h1 { color:#58a6ff; }
h2 { color:#8b949e; font-size:1rem; margin-top:0; }
.card { background:#161b22; border:1px solid #30363d; padding:20px; border-radius:8px; margin-bottom:16px; }
.az-badge { display:inline-block; background:${AZ_COLOR}; color:#fff; padding:4px 12px; border-radius:4px; font-weight:bold; }
.label { color:#8b949e; }
.value { color:#f0883e; }
.hint { color:#6e7681; font-size:0.85rem; margin-top:24px; }
</style></head>
<body>
<h1>The D3LT4 Protocol</h1>
<h2>Lab 02 — ALB + Auto Scaling Group</h2>
<div class="card">
<p><span class="label">Instance ID:</span> <span class="value">$INSTANCE_ID</span></p>
<p><span class="label">Availability Zone:</span> <span class="az-badge">$AZ</span></p>
<p><span class="label">Private IP:</span> <span class="value">$LOCAL_IP</span></p>
</div>
<p class="hint">Si refrescás y cambia el Instance ID o la AZ, el ALB está distribuyendo tráfico entre instancias.</p>
</body>
</html>
HTML
- Click Create launch template
Launch Template
d3lt4-web-templatev1 — AMI Amazon Linux 2, t3.micro, SGd3lt4-asg-sg.
# Guardar el user data en un archivo primero
cat << 'USERDATA' > web-server-lab02.sh
#!/bin/bash
yum update -y && yum install -y httpd stress
systemctl start httpd && systemctl enable httpd
TOKEN=$(curl -s -X PUT "http://169.254.169.254/latest/api/token" -H "X-aws-ec2-metadata-token-ttl-seconds: 21600")
INSTANCE_ID=$(curl -s -H "X-aws-ec2-metadata-token: $TOKEN" http://169.254.169.254/latest/meta-data/instance-id)
AZ=$(curl -s -H "X-aws-ec2-metadata-token: $TOKEN" http://169.254.169.254/latest/meta-data/placement/availability-zone)
LOCAL_IP=$(curl -s -H "X-aws-ec2-metadata-token: $TOKEN" http://169.254.169.254/latest/meta-data/local-ipv4)
echo "<html><body style='background:#0d1117;color:#c9d1d9;font-family:monospace;padding:40px'><h1 style='color:#58a6ff'>D3LT4 — Lab 02</h1><p>Instance: $INSTANCE_ID | AZ: $AZ | IP: $LOCAL_IP</p></body></html>" > /var/www/html/index.html
USERDATA
aws ec2 create-launch-template \
--launch-template-name d3lt4-web-template \
--version-description "v1 - Lab 02 ALB + ASG" \
--launch-template-data '{
"ImageId": "ami-0c02fb55956c7d316",
"InstanceType": "t2.micro",
"KeyName": "d3lt4-key",
"SecurityGroupIds": ["'"$ASG_SG"'"],
"UserData": "'"$(base64 -w 0 web-server-lab02.sh)"'"
}'
Parte 2 — Target Group + Application Load Balancer¶
Qué es un Application Load Balancer¶
Un Application Load Balancer (ALB) opera en la capa 7 (aplicación) del modelo OSI. Entiende HTTP/HTTPS — puede tomar decisiones de routing basadas en el path (/api/* a un target group, /static/* a otro), los headers o el método HTTP. Esto lo diferencia del Network Load Balancer (capa 4, solo TCP/UDP) y del Classic Load Balancer (deprecado).
La arquitectura interna de un ALB tiene tres componentes:
Internet → ALB
├── Listener (puerto 80)
│ └── Rule default: "todo el tráfico → Target Group"
└── Target Group
├── EC2 instancia 1 (us-east-1a)
└── EC2 instancia 2 (us-east-1b)
- Listener: el ALB "escucha" en un puerto. Cada listener tiene reglas que determinan qué hacer con el tráfico.
- Rule: condición + acción. La regla default es "todo el tráfico → forward a este target group". Podés agregar reglas más específicas (path-based routing, host-based routing).
- Target Group: la colección de destinos a los que el ALB envía tráfico.
El ALB hace health checks periódicos a cada target. Si una instancia no responde HTTP 200, el ALB la marca como "unhealthy" y deja de enviarle tráfico hasta que se recupere. Esto es lo que logra alta disponibilidad: si una instancia se cae, el ALB automáticamente deja de mandarle requests sin intervención manual.
El ALB no tiene IP fija
El ALB no tiene una IP pública estática — tiene un DNS name (algo como d3lt4-alb-123456789.us-east-1.elb.amazonaws.com). En producción, apuntás tu dominio con un CNAME o un Alias Record en Route 53 al DNS name del ALB. Nunca hardcodeás la IP porque puede cambiar.
Qué es un Target Group¶
Un Target Group es un grupo de destinos donde el ALB envía tráfico. Los destinos pueden ser instancias EC2, IPs privadas, funciones Lambda, o contenedores ECS.
Lo más importante del Target Group es la configuración de health checks: define cómo el ALB verifica si cada instancia está saludable. Por defecto hace un GET a / en el puerto 80 y espera un HTTP 200. Si falla N veces seguidas, la marca unhealthy. Si pasa M veces seguidas, la vuelve a marcar healthy.
El algoritmo de balanceo default es Round Robin: el primer request va a la primera instancia, el segundo a la segunda, y así cíclicamente. Podés cambiarlo a Least Outstanding Requests (manda el próximo request a la instancia con menos requests en vuelo).
2.1 Crear el Target Group¶
- Ir a EC2 → Target Groups → Create target group
- Choose a target type: Instances
- Target group name:
d3lt4-web-tg - Protocol: HTTP, Port: 80
- VPC:
d3lt4-vpc - Health check settings:
- Protocol: HTTP
- Path:
/ - Healthy threshold:
2(cuántos checks OK seguidos para marcarla healthy) - Unhealthy threshold:
2(cuántos checks fail seguidos para marcarla unhealthy) - Timeout:
5segundos - Interval:
15segundos
- Click Next → Create target group
No registramos targets a mano
Dejamos el target group vacío. El Auto Scaling Group va a registrar y desregistrar instancias automáticamente cuando las lance o las destruya.
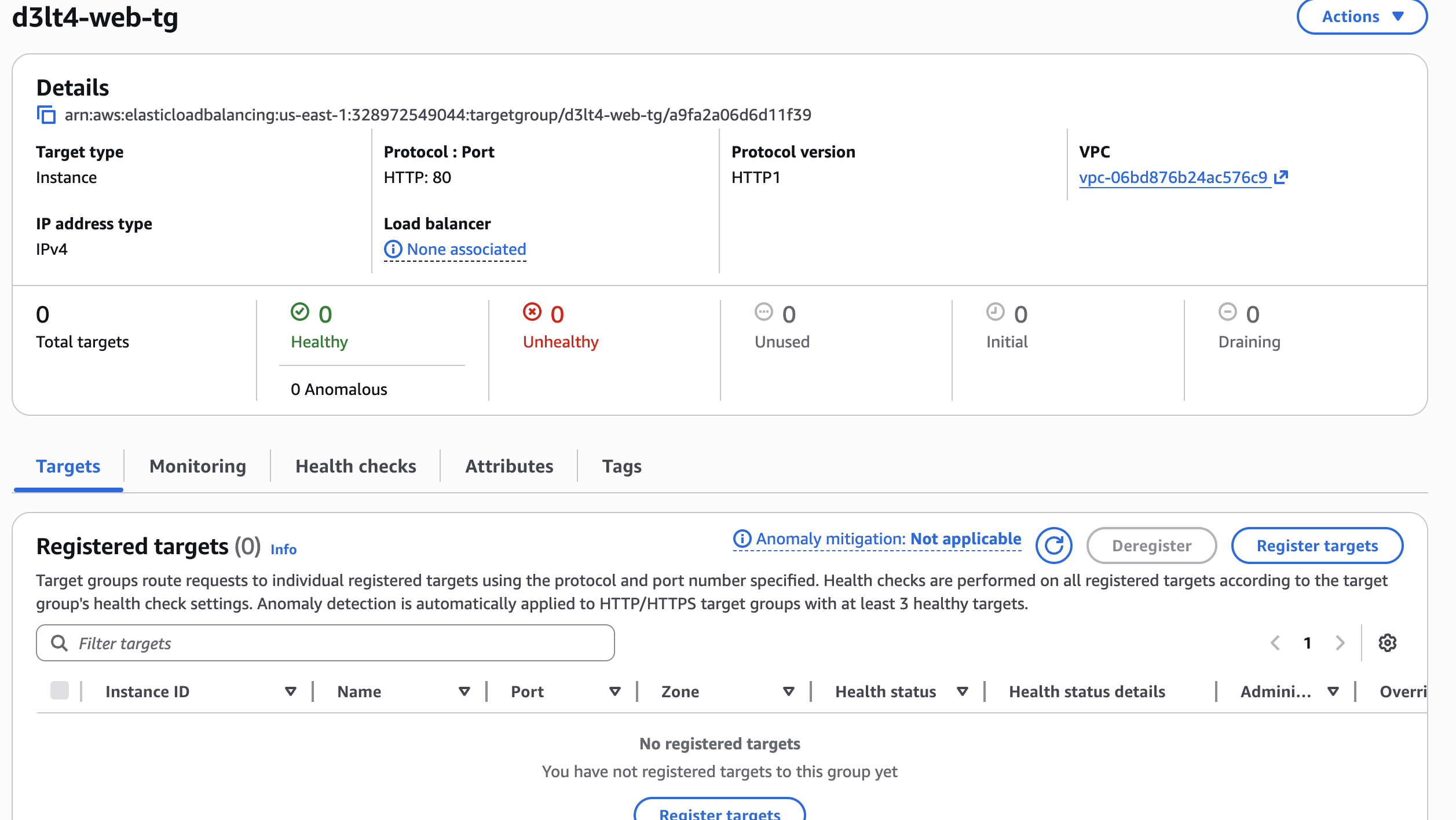
d3lt4-web-tgrecién creado — 0 targets, sin load balancer asociado todavía.
aws elbv2 create-target-group \
--name d3lt4-web-tg \
--protocol HTTP \
--port 80 \
--vpc-id $VPC_ID \
--health-check-protocol HTTP \
--health-check-path / \
--healthy-threshold-count 2 \
--unhealthy-threshold-count 2 \
--health-check-timeout-seconds 5 \
--health-check-interval-seconds 15
# Guardá el ARN del Target Group
export TG_ARN="arn:aws:elasticloadbalancing:us-east-1:XXXX:targetgroup/d3lt4-web-tg/XXXX"
2.2 Crear el ALB¶
El ALB vive en las subnets públicas — necesita ser accesible desde internet. Lo ponemos en 2 AZs para que siga funcionando si una AZ tiene problemas. AWS requiere al menos 2 subnets en AZs distintas para un ALB.
- Ir a EC2 → Load Balancers → Create load balancer
- Seleccionar Application Load Balancer → Create
- Load balancer name:
d3lt4-alb - Scheme: Internet-facing
- IP address type: IPv4
- Network mapping:
- VPC:
d3lt4-vpc - Mappings: seleccionar
us-east-1a→d3lt4-public-1ayus-east-1b→d3lt4-public-1b
- VPC:
- Security groups: quitar el default, seleccionar solo
d3lt4-alb-sg - Listeners and routing:
- Protocol: HTTP, Port: 80
- Default action: Forward to →
d3lt4-web-tg
- Click Create load balancer
- Esperá ~2 minutos hasta que el estado cambie de provisioning a active
ALB
d3lt4-alben estado Provisioning — DNS name asignado, listener HTTP:80 →d3lt4-web-tg.
aws elbv2 create-load-balancer \
--name d3lt4-alb \
--subnets $PUB_SUBNET_A $PUB_SUBNET_B \
--security-groups $ALB_SG \
--scheme internet-facing \
--type application
# Guardá el ARN del ALB
export ALB_ARN="arn:aws:elasticloadbalancing:us-east-1:XXXX:loadbalancer/app/d3lt4-alb/XXXX"
export ALB_DNS="d3lt4-alb-XXXXXXXXX.us-east-1.elb.amazonaws.com"
# Crear el listener: HTTP 80 → Target Group
aws elbv2 create-listener \
--load-balancer-arn $ALB_ARN \
--protocol HTTP \
--port 80 \
--default-actions Type=forward,TargetGroupArn=$TG_ARN
Verificación Parte 2¶
El ALB todavía no tiene targets — el ASG los va a registrar en la Parte 3. Verificamos que esté activo:
Parte 3 — Auto Scaling Group + Scaling Policies¶
Qué es un Auto Scaling Group¶
Un Auto Scaling Group (ASG) es un grupo de instancias EC2 que AWS mantiene y gestiona. Definís tres números:
- Mínimo (min): AWS nunca baja de esta cantidad. Si una instancia se destruye, lanza otra para mantener el mínimo.
- Máximo (max): AWS nunca supera esta cantidad, sin importar cuánto suba la carga. Es tu seguro contra gastos descontrolados.
- Deseado (desired): La cantidad que querés en este momento. Empieza igual al mínimo o al valor que definís.
El ASG monitorea la salud de las instancias usando los health checks del Target Group. Si una instancia falla los health checks, el ASG la destruye y lanza una nueva automáticamente. Esto se llama self-healing — la infraestructura se recupera sola.
El ASG lanza instancias en múltiples subnets/AZs y trata de mantenerlas balanceadas. Si configurás min: 2 con subnets en us-east-1a y us-east-1b, siempre vas a tener al menos una instancia en cada AZ.
Qué son las Scaling Policies¶
Las Scaling Policies definen cuándo y cómo escalar. Hay tres tipos:
| Tipo | Cuándo usarlo |
|---|---|
| Target Tracking | Querés mantener una métrica en un valor objetivo (ej: CPU al 50%). El más simple y el más común. |
| Step Scaling | Querés control granular: "+1 instancia si CPU > 60%, +2 si CPU > 80%". |
| Scheduled Scaling | Sabés de antemano cuándo hay picos: "todos los lunes a las 9am, escalar a 5 instancias". |
Para este lab usamos Target Tracking con CPU al 50%: AWS calcula cuántas instancias necesitás para que el promedio de CPU se mantenga cerca del 50%, y agrega o quita instancias automáticamente.
3.1 Crear el Auto Scaling Group¶
- Ir a EC2 → Auto Scaling Groups → Create Auto Scaling group
Step 1 — Choose launch template:
- Auto Scaling group name:
d3lt4-web-asg - Launch template:
d3lt4-web-template→ Version: Latest (1) - Next
Step 2 — Choose instance launch options:
- VPC:
d3lt4-vpc - Availability Zones and subnets: seleccionar
d3lt4-private-1ayd3lt4-private-1b
ASG en subnets privadas
Las instancias del ASG van en las subnets privadas — internet no puede llegar a ellas directamente, solo el ALB puede. El ALB vive en las públicas y hace de único punto de entrada. Esta es la arquitectura correcta para producción. Para que las instancias puedan bajar paquetes (yum update) durante el arranque, usan la NAT Instance del Lab 01.
- Next
Step 3 — Configure advanced options:
- Load balancing: Attach to an existing load balancer
- Existing load balancer target groups:
d3lt4-web-tg - Health checks: activar Turn on Elastic Load Balancing health checks
ELB health checks vs EC2 health checks
Por defecto el ASG usa EC2 health checks (si la instancia está en estado running, está "healthy"). Con ELB health checks activados, el ASG también considera si el ALB la ve healthy. Esto es mejor: si tu app crashea pero la instancia sigue corriendo, el EC2 check no se entera, pero el ELB check sí.
- Next
Step 4 — Configure group size and scaling:
- Desired capacity: 2
- Minimum capacity: 1
- Maximum capacity: 4
- Automatic scaling:
- Seleccionar Target tracking scaling policy
- Scaling policy name:
cpu-target-tracking - Metric type: Average CPU utilization
- Target value: 50
- Instance warmup: 60 segundos
Instance warmup
El ASG espera este tiempo antes de medir el CPU de una instancia nueva. Sin esto, el User Data (que consume CPU mientras instala paquetes) podría disparar otro scale-out mientras la instancia todavía está arrancando.
- Next → Next → Create Auto Scaling group
ASG
d3lt4-web-asg— Desired: 2, Version 2 del Launch Template, Activity con los 2 launches exitosos.
aws autoscaling create-auto-scaling-group \
--auto-scaling-group-name d3lt4-web-asg \
--launch-template LaunchTemplateName=d3lt4-web-template,Version='$Latest' \
--min-size 1 \
--max-size 4 \
--desired-capacity 2 \
--vpc-zone-identifier "$PRIV_SUBNET_A,$PRIV_SUBNET_B" \
--target-group-arns $TG_ARN \
--health-check-type ELB \
--health-check-grace-period 60
# Agregar la scaling policy de Target Tracking
aws autoscaling put-scaling-policy \
--auto-scaling-group-name d3lt4-web-asg \
--policy-name cpu-target-tracking \
--policy-type TargetTrackingScaling \
--target-tracking-configuration '{
"PredefinedMetricSpecification": {
"PredefinedMetricType": "ASGAverageCPUUtilization"
},
"TargetValue": 50.0,
"EstimatedInstanceWarmup": 60
}'
3.2 Habilitar Detailed Monitoring¶
Este paso es obligatorio antes de hacer el stress test.
Por defecto, EC2 usa Basic Monitoring: CloudWatch recopila métricas de CPU cada 5 minutos. Con Target Tracking al 50% y un stress test de 5 minutos, CloudWatch todavía no tiene datos suficientes para disparar el scaling — y no escala nada.
Detailed Monitoring baja el intervalo a 1 minuto, haciendo al ASG mucho más reactivo.
Hacé esto en cada instancia del ASG:
- EC2 → Instances → seleccionar la instancia
- Actions → Monitor and troubleshoot → Manage detailed monitoring
- Tildar Enable → Confirm
- Repetir para la segunda instancia
# Habilitar detailed monitoring en todas las instancias del ASG
for id in $(aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-names d3lt4-web-asg \
--query 'AutoScalingGroups[0].Instances[].InstanceId' \
--output text); do
aws ec2 monitor-instances --instance-ids $id
echo "✓ detailed monitoring habilitado en $id"
done
Sin esto el stress test no funciona
Con basic monitoring (5 min), el stress test termina antes de que CloudWatch tenga datos suficientes para disparar el scaling. Siempre habilitá detailed monitoring antes de probar auto scaling en labs.
3.3 Verificar que las instancias están healthy¶
Esperá 3-5 minutos para que el ASG lance las 2 instancias y el ALB haga los health checks.
- EC2 → Auto Scaling Groups →
d3lt4-web-asg→ pestaña Activity — vas a ver los eventos de launch - EC2 → Target Groups →
d3lt4-web-tg→ pestaña Targets — las 2 instancias deben aparecer como Healthy
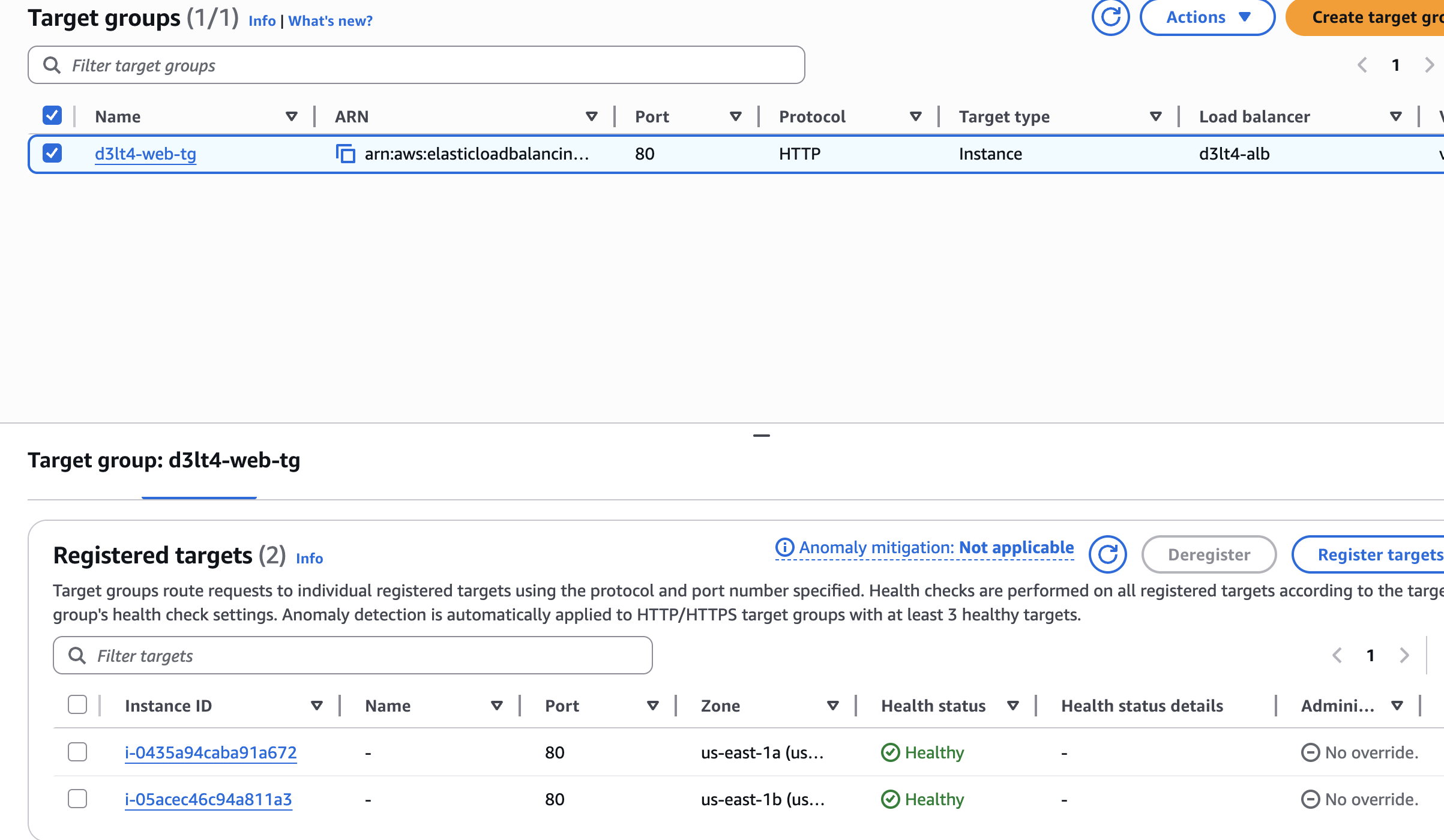
d3lt4-web-tg— 2 instancias registradas, una en us-east-1a y otra en us-east-1b, ambas Healthy.
# Estado del ASG
aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-names d3lt4-web-asg \
--query 'AutoScalingGroups[0].Instances[].{id:InstanceId,health:HealthStatus,state:LifecycleState}' \
--output table
# Estado de los targets en el ALB
aws elbv2 describe-target-health \
--target-group-arn $TG_ARN \
--query 'TargetHealthDescriptions[].[Target.Id,TargetHealth.State]' \
--output table
3.4 Probar el ALB y el balanceo¶
Con los targets healthy, verificamos que el ALB está distribuyendo tráfico.
- Copiá el DNS name del ALB desde EC2 → Load Balancers →
d3lt4-alb - Abrí el browser y entrá a
http://<DNS_DEL_ALB> - Deberías ver la página D3LT4 con el Instance ID y la AZ de una de las instancias
- Refrescá varias veces (Ctrl+F5) — el Instance ID y la AZ deberían cambiar entre las dos instancias
¿Por qué no cambia siempre al refrescar?
Los browsers mantienen conexiones HTTP persistentes (keep-alive). Para forzar la rotación entre instancias, usá curl desde la terminal:
Primera respuesta — instancia en
us-east-1b, IP10.0.4.221.
Al refrescar — instancia distinta en
us-east-1a, IP10.0.3.230. El ALB está distribuyendo en round-robin.
3.5 Stress test — probar el scale-out¶
Ahora lo más entretenido: simular carga alta para ver cómo el ASG lanza instancias nuevas automáticamente.
Primero obtené las IPs privadas de las instancias del ASG. En EC2 → Instances, filtrá por el Launch Template o buscá las instancias sin nombre fijo que aparecieron después de crear el ASG.
Conectate a ambas usando la NAT Instance como bastion (igual que en el Lab 01):
# Terminal 1 — instancia en us-east-1a
ssh -o ProxyCommand="ssh -i d3lt4-key.pem -W %h:%p ec2-user@<IP_PUBLICA_NAT>" \
-i d3lt4-key.pem ec2-user@<IP_PRIVADA_INSTANCIA_1>
# Terminal 2 — instancia en us-east-1b
ssh -o ProxyCommand="ssh -i d3lt4-key.pem -W %h:%p ec2-user@<IP_PUBLICA_NAT>" \
-i d3lt4-key.pem ec2-user@<IP_PRIVADA_INSTANCIA_2>
En ambas terminales, ejecutá el stress test simultáneamente:
Stress corriendo en la instancia de
us-east-1b— 2 cpu hogs despachados.
Stress corriendo simultáneamente en
us-east-1a— ambas instancias al 100% de CPU.
Mientras corre, monitoreá el ASG en paralelo:
- EC2 → Auto Scaling Groups →
d3lt4-web-asg→ pestaña Activity — esperá eventos de "Launching a new EC2 instance" - EC2 → Auto Scaling Groups →
d3lt4-web-asg→ pestaña Monitoring → EC2 → ver la métrica CPU Utilization
El scale-out no es instantáneo
Con detailed monitoring habilitado (1 min), CloudWatch detecta la alarma en ~2-3 minutos. El ASG tarda ~30-60 segundos en decidir escalar. La instancia nueva tarda ~2-3 minutos en arrancar y pasar los health checks.
Total: esperá ~5 minutos antes de ver las nuevas instancias en el Target Group.
Métrica CPU Utilization en CloudWatch — pico de 85.5%, el ASG actualizando capacity de 2 a 4.
Activity log del ASG — 2 instancias nuevas lanzadas por la alarma TargetTracking, en estado "Waiting for instance warmup".
Una vez que termina el stress test, observá el scale-in: el ASG espera el cooldown period (300 segundos por defecto) antes de destruir instancias, para evitar "flapping" — escalar y desescalar constantemente si el CPU oscila alrededor del umbral.
Scale-in en acción — el ASG terminando instancias de 4→3→2. La causa: alarma TargetTracking detectó CPU bajo el umbral sostenidamente.
Verificación Parte 3¶
- Detailed Monitoring habilitado en ambas instancias del ASG
- Las 2 instancias del ASG aparecen como Healthy en el Target Group
-
http://<DNS_ALB>muestra la página D3LT4 con los datos de la instancia - Refrescar varias veces (o curl en loop) cambia el Instance ID entre instancias (round-robin)
- Durante el stress test, la CPU subió a ~85% y el ASG escaló a 4 instancias
- Después de ~15 minutos con CPU baja, el ASG volvió a 2 instancias (scale-in automático)
Limpieza¶
El ALB cobra por hora
A diferencia del Lab 01, el ALB no es Free Tier — cobra ~USD $0.008/hora más costo por LCU. Eliminalo cuando no estés practicando. Las EC2 t2.micro del ASG sí son Free Tier.
El orden importa: primero el ASG (para terminar las instancias), después el ALB.
- EC2 → Auto Scaling Groups →
d3lt4-web-asg→ Delete → confirmar (Esto termina automáticamente todas las instancias del ASG) - EC2 → Load Balancers →
d3lt4-alb→ Actions → Delete load balancer → confirmar - EC2 → Target Groups →
d3lt4-web-tg→ Actions → Delete → confirmar
# 1. Borrar el ASG (--force-delete termina las instancias sin esperar lifecycle hooks)
aws autoscaling delete-auto-scaling-group \
--auto-scaling-group-name d3lt4-web-asg --force-delete
# 2. Borrar el ALB
aws elbv2 delete-load-balancer --load-balancer-arn $ALB_ARN
# 3. Esperar a que el ALB se elimine antes de borrar el Target Group
aws elbv2 wait load-balancers-deleted --load-balancer-arns $ALB_ARN
# 4. Borrar el Target Group
aws elbv2 delete-target-group --target-group-arn $TG_ARN
Lo que dejamos corriendo (gratis)
- VPC, subnets, IGW, Route Tables → siempre gratis
- NAT Instance (
d3lt4-nat-instance) → t2.micro Free Tier, parala cuando no practiques - Launch Template → gratis, no tiene costo por existir
Actualizar mis-recursos.sh¶
Agregá estas variables al archivo mis-recursos.sh del Lab 01:
# Lab 02
export ALB_SG="sg-XXXXXXXXX" # d3lt4-alb-sg
export ASG_SG="sg-XXXXXXXXX" # d3lt4-asg-sg
export TG_ARN="arn:aws:elasticloadbalancing:us-east-1:XXXX:targetgroup/d3lt4-web-tg/XXXX"
export ALB_ARN="arn:aws:elasticloadbalancing:us-east-1:XXXX:loadbalancer/app/d3lt4-alb/XXXX"
export ALB_DNS="d3lt4-alb-XXXXXXXXX.us-east-1.elb.amazonaws.com"
Resumen de conceptos clave¶
| Concepto | Detalle |
|---|---|
| SPOF | Single Point of Failure. Un solo componente que si falla, cae todo. El ALB + ASG eliminan el SPOF de las instancias. |
| ALB vs NLB | ALB = capa 7 (HTTP/HTTPS, path/host routing). NLB = capa 4 (TCP/UDP, ultra baja latencia). CLB = deprecated. |
| Listener | El ALB escucha en un puerto. Cada listener tiene reglas que determinan a qué Target Group enviar el tráfico. |
| Target Group | Colección de destinos con health checks. Round Robin por defecto. |
| Health check | ALB hace GET a / cada 15s. 2 OK seguidos → healthy. 2 fail seguidos → unhealthy → deja de mandar tráfico. |
| ELB vs EC2 health checks | EC2 check: ¿la instancia está running? ELB check: ¿tu app responde HTTP 200? El ELB check detecta crashes de app. |
| DNS name del ALB | El ALB no tiene IP fija. En producción apuntás un CNAME o Alias Record de Route 53 al DNS name. |
| Launch Template | Blueprint para EC2. Versionable. El ASG lo usa para lanzar instancias idénticas. |
| ASG — min/desired/max | Min: garantía de disponibilidad. Desired: estado actual. Max: límite de costo. |
| Self-healing | Si una instancia falla el health check, el ASG la destruye y lanza una nueva automáticamente. |
| Target Tracking | Scaling policy que mantiene una métrica en un valor objetivo. La más simple de configurar. |
| Instance warmup | Tiempo que el ASG espera antes de medir el CPU de una instancia nueva. Evita scale-out espurio durante el arranque. |
| Cooldown period | Tiempo que espera el ASG antes de volver a escalar. Evita flapping. 300s por defecto. |
| SG source = otro SG | En vez de una IP como source, referenciás otro SG. Si las IPs del ALB cambian, la regla sigue funcionando. |
| Subnets privadas para instancias | Las EC2s del ASG van en subnets privadas — solo el ALB puede llegar a ellas por HTTP. |
| Basic vs Detailed Monitoring | Basic: métricas cada 5 min (default). Detailed: cada 1 min. Obligatorio habilitar Detailed para que el auto scaling funcione en labs. |
| Scale-in conservador | Target Tracking espera 15 min consecutivos con CPU bajo el umbral antes de terminar instancias. Es intencional para evitar flapping. |